
はじめまして、データサイエンティストのますみです!

最近、300万行くらいの表データの分析を行う機会があり、その際に非常に苦戦した「高速化の方法」についてこの記事にまとめます。まだそんな大きなデータ扱わないという方でも、普段から本記事にまとめた書き方を心がける(書く習慣をつける)とスキルがワンランク上がるかと思います。
1. サンプルデータの生成
まず計算速度を比較するためには、大量のレコードデータを生成する必要があります。
本記事では「-100から100までの範囲のランダムな値が入った100行 x 3列の配列データ」を生成しました。
import numpy as np
import pandas as pd
data_row = 1000000
raw_np = np.random.randint(-100, 100, (data_row, 3))
raw_df = pd.DataFrame(data=raw_np, columns=['column_1', 'column_2', 'column_3'])
print('raw_df')
display(raw_df)
2. 計算速度を計測する関数の定義
次に、計算速度を計測するための関数を定義しました。
もしも第一引数で開始時間が渡されれば、差分の時間を出力します。
もしも第一引数が空の場合は、現在の時間を出力します。
関数が正しく動作しているかを確認するために、テストを行いました。
3秒sleepさせているため、約3.0の出力がされれば、成功です。
# 「計算速度を計測する関数」を定義
import time
def measure_time(start_time=''):
if start_time == '':
return time.time()
else:
return time.time() - start_time
# 「計算速度を計測する関数」のテスト
is_debug = True
if is_debug:
start_time = measure_time()
time.sleep(3)
duration_time = measure_time(start_time)
print(duration_time)
# Output: 3.00310707092285163. 高速化したい計算内容
本記事では、以下のような”Min-Max Normalization”の計算を3列目に対して、計算する例を考えます。
1列目と2列目は今回使用しないのですが、仕事の現場でしばしばこのような計算の対象外の列が含まれていることもあるため、そのような状況も想定してデータ生成をしています。
Min-Max Normalizationは、一般的な正規化にあたります。
正規化は「最小値を0、最大値を1とする0~1にスケーリングさせる手法」です。
$$x’ = \frac{x – min(x)}{max(x) – min(x)}$$
Scikit-learnのMinMaxScalerを使えば、とても簡便に計算ができますが、今回は計算速度の比較を行いたいため、以下のように3列目に対して、以下のように自前のコードの実装をします。
# 最小値と最大値を事前に計算
min_column_3 = min(raw_df.column_3)
max_column_3 = max(raw_df.column_3)
# 正規化された値を計算
norm_column_3 = (row.column_3 - min_column_3) / (max_column_3 - min_column_3)4. アルゴリズムの速度比較
それでは、前置きが長くなりましたが、5つのアプローチを比較していきたいと思います。
4-1. iterrowsを使った書き方(numpy配列にappend)
このアプローチは、iterrowsを用いて空のnumpy配列にappend(末尾に追加)して、最後に新しい”columns_3_norm”という列に格納する方法です。
temp_df = raw_df.copy()
start_time = measure_time()
norm_column_3_array = np.array([])
for index, row in temp_df.iterrows():
norm_column_3 = (row.column_3 - min_column_3) / (max_column_3 - min_column_3)
norm_column_3_array = np.append(norm_column_3_array, norm_column_3)
temp_df['columns_3_norm'] = norm_column_3_array
duration_time = measure_time(start_time)
print(f'{duration_time} sec')
# Output: 1050.1790993213654 sec4-2. iterrowsを使った書き方(pythonのlistにappend)
このアプローチは、iterrowsを用いて空のlist(配列)にappend(末尾に追加)して、最後に新しい”columns_3_norm”という列に格納する方法です。
たったこれだけの違いで、計算時間が7/100になりました!
ここで速くなった理由として、numpy配列(array)はappendされる度に固定長のメモリを再確保する必要があります(C言語ベースなため)。一方で、listは、pythonにより可変長にメモリ確保がされているため、appendするときにメモリの再確保をする必要がありません。そのため、numpy arrayよりもlistの方が速いと考えられます。
配列にappendするときは、numpy配列(array)ではなく、listを使う。
temp_df = raw_df.copy()
start_time = measure_time()
norm_column_3_list = []
for index, row in temp_df.iterrows():
norm_column_3 = (row.column_3 - min_column_3) / (max_column_3 - min_column_3)
norm_column_3_list.append(norm_column_3)
temp_df['columns_3_norm'] = norm_column_3_array
duration_time = measure_time(start_time)
print(f'{duration_time} sec')
# Output: 74.43075776100159 sec4-3. 事前にnumpy配列に格納する書き方
このアプローチは、事前に計算対象となる列のデータをnumpy配列に格納してからループを回す方法です。これまで使っていたiterrowsから脱却していることが大幅に速度改善されている理由になります。
たったこれだけの違いで、4-2の計算時間の7/100になりました!(4-1の計算時間の5/1000!)
ここで速くなった理由は、pandasのiterrowsよりも事前確保されたnumpy配列をfor文で回した方が速いからです。
DataFrameのFor文を回すときは、iterrowsではなく、事前確保したnumpy配列を使う。
temp_df = raw_df.copy()
start_time = measure_time()
norm_column_3_list = []
columns_3_array = temp_df.column_3
for index in range(temp_df.shape[0]):
temp = columns_3_array[index]
norm_column_3 = (temp - min_column_3) / (max_column_3 - min_column_3)
norm_column_3_list.append(norm_column_3)
temp_df['columns_3_norm'] = norm_column_3_array
duration_time = measure_time(start_time)
print(f'{duration_time} sec')
# Output: 4.97247314453125 sec4-4. 事前にnumpy配列に格納する書き方(事前にgetattr)
このアプローチは、4-3のiterrowsから脱却しながら、なおnumpy配列を取得するときに、.valuesを使っている方法です。
たったこれだけの違いで、4-3の計算時間の24/100になりました!(4-1の計算時間の1/1000!)
この方法が速い理由として、for文の中で毎回__getattr__というメソッドを呼び出さなくて済むことが挙げられます。ちょっとした工夫ですが、ぜひ実践してみてください。
列データを配列化するときは、.valuesをつけて、attributeを事前取得する。
temp_df = raw_df.copy()
start_time = measure_time()
norm_column_3_list = []
columns_3_array = temp_df.column_3.values # ここに.valuesを追加
for index in range(temp_df.shape[0]):
temp = columns_3_array[index]
norm_column_3 = (temp - min_column_3) / (max_column_3 - min_column_3)
norm_column_3_list.append(norm_column_3)
temp_df['columns_3_norm'] = norm_column_3_array
duration_time = measure_time(start_time)
print(f'{duration_time} sec')
# Output: 1.1823489665985107 sec5. 計算時間の比較まとめ
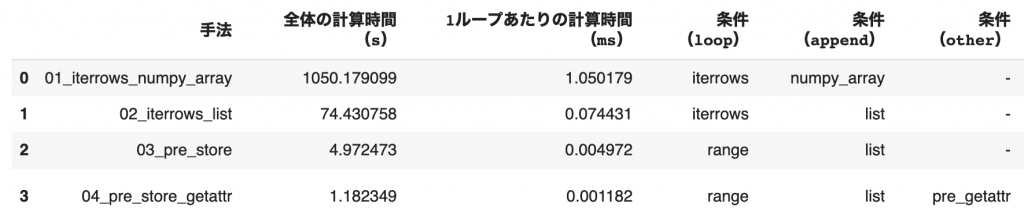
今回の実験により、コードの書き方によって、計算速度が約1000倍も変わってしまうことがわかりました。
「ビッグデータ分析」や「機械学習(特に深層学習)のパラメータ最適化」を行うデータサイエンティストに対して、本記事がお役に立てば幸いです。
最後に
いかがだったでしょうか?
この記事を通して、少しでもあなたの困りごとが解決したら嬉しいです^^
📩 仕事の相談はこちら 📩
お仕事の相談のある方は、下記のフォームよりお気軽にご相談ください。
問い合わせフォームはこちら
もしもメールでの問い合わせの方がよろしければ、下記のメールアドレスへご連絡ください。
info*galirage.com(*を@に変えてご送付ください)
🎁 「生成AIの社内ガイドライン」PDFを『公式LINE』で配布中 🎁
「LINEで相談したい方」や「お問い合わせを検討中の方」は、公式LINEでご連絡いただけますと幸いです。
(期間限定で配信中なため、ご興味ある方は、今のうちに受け取りいただけたらと思います^^)
公式LINEはこちら
🚀 新サービス開始のお知らせ 🚀
新サービス 「AI Newsletter for Biz」 がスタートしました!
ビジネスパーソン向けに「AIニュース」を定期配信する完全無料のニュースレターです📩
ますみが代表を務める「株式会社Galirage」では、「生成AIを用いたシステムの受託開発(アドバイス活動含む)」をしています。
そこでお世話になっているお客様に対して、「最新トレンドを加味したベストな提案」をするために、日々最新ニュースを収集する仕組みを構築していました。
今回は、そこで構築した仕組みを活用して、より多くの人に有益な情報を届けたいと思い、本サービスを開始しました!
一人でも多くの方にとって、「AI人材としてのスキルアップ」につながれば幸いです^^
▼ 登録はこちらから ▼
https://bit.ly/ai_newsletter_for_biz_ai_lab

補足資料(jupyter notebook)
速度比較がしやすいように、notebookの方を以下のディレクトリに公開しました。
https://github.com/Masumi-M/lets_speed_up_python

